Common Crawl¶
Crawled websites in the Common Crawl dataset are stored in WARC Web ARChive format. The Common Crawl archive used in this project is divided into 66.500 parts, each containing on average 46.000+ WARC records so in total 3.07+ billion Web pages.
URL Index¶
To not being forced to download and look into all crawled data, Common Crawl provides an URL Index for the crawled Web pages.
For example if we lookup http://www.uni-freiburg.de/ we get.
{
"digest": "VJOEXKZAJQ56LKVB7ZP3WHQJ7YWU7EIX",
"filename": "crawl-data/CC-MAIN-2017-13/segments/1490218187945.85/warc/CC-MAIN-20170322212947-00421-ip-10-233-31-227.ec2.internal.warc.gz",
"length": "17128",
"mime": "text/html",
"offset": "726450631",
"status": "200",
"timestamp": "20170324120615",
"url": "http://www.uni-freiburg.de/",
"urlkey": "de,uni-freiburg)/"
}
now we can use filename, offset and length to download only this fetched site from the archive. For
example using curl
curl -s -r<offset>-$((<offset>+<length>-1)) "<archive_base><file_name>" >> "<out_file>"
Common Crawl even provides a server with an API to retrieve the WARC file locations.
Fetch university WARC file locations¶
endSly/world-universities-csv provides a source of currently 9363 university web sites from all over the world. The index_fetcher.py provides a tweaked version of ikreymer/cdx-index-client to fetch the warc file locations for domains provided by the world-universities.csv file.
Download the WARC files¶
After fetching the locations of the WARC files in the Common Crawl archive: src/download_warc.py downloads the WARC files and stores
them compressed. Use NUM_PARALLEL_JOBS to adjust how many parallel jobs should be executed at the same time.
Coverage in Common Crawl¶
During the project the question raised how many of the personal Web pages are in the common Crawl archive. Generally we know that in each iteration crawls overlap to some degree with its predecessors. For example in the April 2017 archive 56% of the crawled URLs overlap with the March 2017 crawl (as stated in the April 2017 crawl announcement).
To evaluate the coverage for a certain host, we collected 342 urls for scientists personal Web pages on the uni-freiburg.de domain and checked if they are present in the different crawls. For all indexes (Summer 2013 till June 2017) combined 46,7% of the sample sites where covered. Figure 8 shows the matches of the 164 out of 342 samples with at least one match in a crawl archive. Figure 9 contains the total coverage for each crawl and the combined coverage for each crawl and the union with its predecessors.
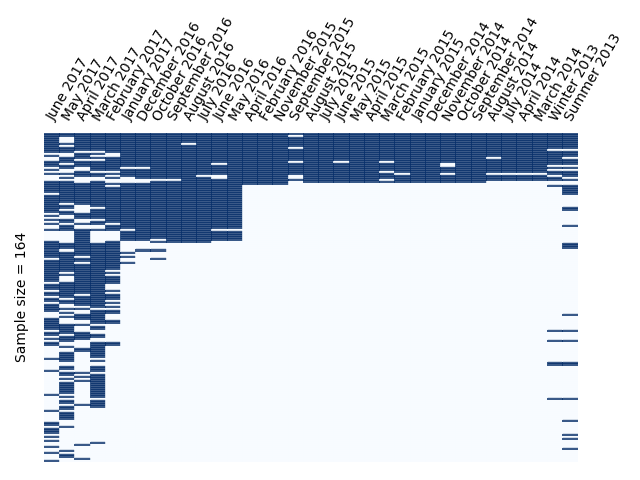
Figure 8: Coverage matrix for the 164 samples with at least one match in a crawl.
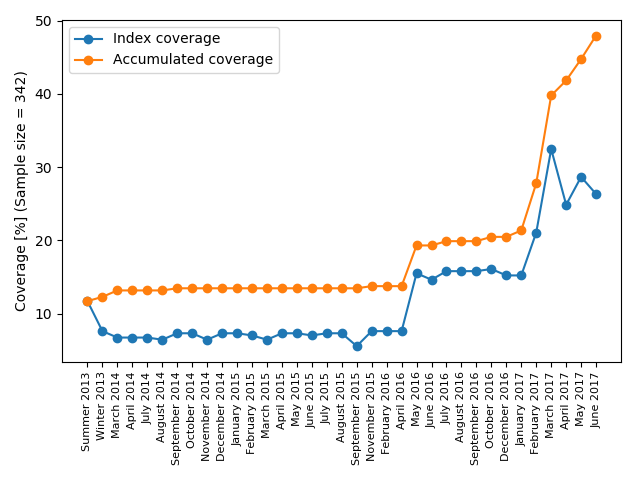
Figure 9: Plots of sample URL coverage. Total coverage for single crawl archives and coverage for the union of the crawl archive and its predecessors.
To reproduce the results yourself or for another set of URLs you can use evaluate_common_crawl_coverage.py to evaluate the coverage for a list of URLs.