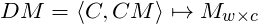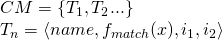This project models the meanings of words based on how those words are used in a large corpus. The meaning-representation supports both equality and distance comparisons, as well as other operations from linear algebra. Some of these operations can be used for semantic comparisons and can thus be used for detection of related, and perhaps even synonymous, word pairs. Various tests of correspondence between human judgments of semantic similarity and the project’s output place it among similar systems, though not at the top.
Introduction
The idea for this project arose during a discussion of one of the challenges in information extraction. Information extraction attempts to build structured representations, such as tables, culled from unstructured data, such as web pages. One problem when attempting to extract structured information from natural language is that the mapping between graphical representation (words) and meaning is many-to-many; that is, given a meaning (say the idea of physical vigorousness), we do not know which graphical form was used to convey it (strong, mighty or muscular are equiprobable candidates) and similarly, given a graphical form, we often do not know for certain the meaning that was intended, but rather we know a set of possible senses. Linguists have given names to these phenomena; the first is called synonymy and the second polysemy.
Making matters harder still, the problem of assigning meaning to graphical forms cannot be solved by perfect knowledge of the map between the two sets. In order to understand phrases and multi-word expressions like ‘house boat’, we need not only to understand the meanings of ‘house’ and ‘boat,’ but also how those meanings combine to form the phrase’s meaning. The analysis of how the meaning of phrases is composed from the meanings of component words is called semantic composition.
To get a flavor for how these challenges are practically important, consider this example. Let’s pretend that the wonderfully useful Internet Movie Database website doesn’t exist and an enterprising computational linguist wants to create such a database, but is too lazy to compile the information manually. Instead, their plan is to write a program that can search the web, recognize when the text asserts pertinent facts, and extract those facts and store them in tabular form. In addition to a table of actors and another of movies, there would likely also be a table representing the involvement of actors in films. Our entrepreneur might first attempt to build this table by using a pattern such as <Actor, AppearIn, MovieTitle>, which would correctly match sentences like Johnny Depp appeared in Pirates of the Caribbean, assuming entity recognition software identified Johnny Depp as an actor and Pirates of the Caribbean as a movie (another vexing problem unto itself). It would seem then that the problem is merely to define such a set of patterns. But, in fact, it is not trivial at all to do so; there are an astoundingly large number of ways to express this simple relationship between an actor and a movie. Not only is the set of phrases similar to appear in large and potentially growing (to star in is one other member of this set), but there is no guarantee that the sentence will have any particular structure; the fact itself might not be the subject of the sentence but an aside in a relative clause. So, too, might this same fact be expressed using a relation between movies and actors (e.g. to feature).
<div id="title-main">
<h1 class="headline">
Lea Michele To Appear In ‘Sons Of Anarchy’
</h1>...
Fig. 1 An example of HTML extracted from The Hollywood News corresponding to the extraction <Lea Michele, AppearIn, Sons of Anarchy>.
<div class="storyHead">
<h1 itemprop="headline name">
Hollywood star Shia LaBeouf appears in court after arrest at Broadway show
</h1>...
Fig. 2 An example of HTML extracted from The Telegraph showing text that might be inappropriately extracted as <Shia LaBeouf, AppearIn, court>.
The project takes as its goal something quite a bit smaller in scope than the entire discipline of information extraction. Instead, the focus is on building a representation of the meanings of individual words, as an accurate representation of the meaning of words is a useful starting point. Such a representation could be used to recognize when relations like to appear in and to star in are equivalent.
The remainder of this paper is structured as follows. First, we will cover some background on distributional semantics, a linguistic theory of how to capture the meaning of words, and how one sort of distributional model may be constructed. Then, we will review the structure of the project itself, with respect to its various components and how to use them. Then, we will look at some standard benchmarks, to see how the model compares to similar work.
Background
For the last 20 years, interest in distributional models of semantic representation has grown. Although in some respects, these models differ greatly, they are the same with respect to one defining attribute: all assume that the degree of semantic similarity between two words is a function of the overlap of their contexts, an idea known as the distributional hypothesis, where distribution refers to the collection of all contexts of a given word.
Distributional models (DMs) have now been successfully used to account for many sorts of semantic phenomena including attributional similarity (similarity in meaning of words derived from similarity in attributes, e.g. dogs and puppies both have tails) and relational similarity (similarity in meaning of pairs of words, e.g. dog is to puppy as chicken is to chick). Additionally, DMs have also been used to derive concepts (by examining the set of attributes used with a given word) and to compare verb selection preferences (by comparing the relative frequency of noun and verb co-occurrence).
Though all DMs subscribe to the distributional hypothesis and therefore try to model context, they differ a great deal with respect to what their models of context look like. The simplest models use a window of words centered around the target word that extends a finite distance in either direction in the sentence. This not only works well but has the advantage of being easy to compute. In this project, rather than using a window of words in the sentence, we use another popular alternative, a window within a grammatical representation of the sentence. The idea is that the presence of words within a certain distance radius is a noisy signal, as only a fraction of the words in a given phrase have connections betweem them that are actually meaningful, and that grammatical relationships are likely to be less noisy. Unfortunately, building grammatical representations is computationally expensive when corpora are large (which they must be in order to ensure adequate coverage for all words) and the quality of these representations is an unavoidable bottleneck on overall performance. The notion of context needn't be relegated to just words, though it is in this project. It is also possible, and perhaps even a good idea, to incorporate less granular contexts, such as the latent topics of the paragraph or document. Images can serve as context as well.
DMs models vary not only with respect to how they model context but also with respect to their representation. In this project, we use a vector-based representation, in which the dimensions stand for contexts and the coordinates are a function of co-occurrence frequency. One advantage of using vectors is it affords powerful tools from linear algebra. For example, one popular method of comparing vectors, which is to serve as a proxy for the semantic similarity between them, is to take their cosine. High-performing DMs have also been constructed using neural network representations and graph-based models.
A simple example demonstrating how a vector representing the meaning of lamb would be constructed if the corpus consisted of the nursery rhyme Mary had a little lamb and the context model was a 3-word window on either side of the target is shown below.
Fig. 3 The process of creating a co-occurrence vector for a given word from a corpus using a fixed window-size of 3.
Building the Co-Occurrence Matrix
The project consists of a (1) a distributional component and (2) a semantic space component. The distributional component, which will be explained in the following section, is responsible for constructing a co-occurrence matrix, as in the above graphic. Formally, it is a function that accepts two elements, a corpus and a context model, and produces a co-occurrence matrix.
Fig. 4 The distributional component is a function that accepts a corpus and a context model and creates a co-occurrence matrix, the rows of which stand for words and the columns of which are contexts.
The Corpus
The corpus is often a collection of documents. For example, there are corpora constructed from Wikipedia and from articles that appeared in the New York Times newspaper. However, for this project, we used part of the Google Syntactic N-Grams corpus. Google’s Syntactic N-Gram corpus is notable for two reasons: firstly, it is rather large. The corpus has over 10 billion English tokens as compared with, for example, a corpus derived from Wikipedia that has 800 million and the Corpus of Contemporary American English, which has 450 million (there are many other corpora). In addition to its distinctive size, the Syntactic N-Gram corpus is further distinguished by the fact that it consists not of sentences but parts of already-parsed sentences. Given that the context-model here requires grammatical relationships, this saves a lot of time. For a corpus of this size, the task of creating such a grammatical representation is quite expensive. For example, a computing cluster here was able to parse the smaller Wikipedia corpus in two weeks. Additionally, the creators of the dataset intentionally offer tree fragments, instead of entire parse trees, because while the latter would be more flexible in their application, the former are sufficient for many tasks while also being much more computationally manageable.
The corpus consists of sets of parse tree-fragments that vary with respect to the number of content-words (“meaning-bearing words”) and the presence of functional markers. For this project, we use the subset of tree-fragments consisting of three content-words without functional markers. See the figure 6 below for an example. This subset, each example of which contains three words connected by two grammatical relationships, is known as the biarcs subset. The name biarcs (as well as the names of other subsets, including the arc subset), refers to a graphical representations of sentence structure, in which words are nodes connected by arcs (which we refer to hereafter as edges). The decision to use this subset, as opposed to subsets with more or fewer content-words, reflects the sort of phenomena being modeled. Whereas, for instance, the nodes subset, which consists of single content-words and dependency relations, can capture syntactic relations and the arcs subset, which consists of two content-words connected by a single edge, can capture patterns between words using specific dependency relations, the biarcs subset is capable of capturing subject-verb-object triplets. The desirability of this property is explored in greater depth later, when discussing the context model.
Dependency Parse Trees
Briefly, dependency parse trees are representations of the grammatical structure within a sentence. Technically, a dependency parse tree is a connected acyclic graphs in which the nodes are words and the edges are directed. Unlike the constituency relation, which is the basis for constituency parse trees, and which treats the sentence as a collection of phrases and nested phrases, the dependency relation is a one-to-one relationship, such that every word has a single head or governor. There is as of yet no standard theory for grammatical dependencies and many popular theories are still actively being revised.
Fig. 5 The Stanford dependency parser's output for Mary had a little lamb. Here, the direction of the arrow points from governor to dependent. This is a complete dependency parse tree. The input to the project, however, was a collection of 'biarcs' -- generally, connected subgraphs of three nodes, such as the path from Mary to lamb through had. An example of a biarc can be found in figure 5.
The Context Model
As mentioned earlier, the distributional component is a function that accepts a corpus and a context model and which returns a co-occurrence matrix. In this section, we describe the context model, which is responsible for defining which sorts of contexts in the corpus are meaningful, and which must therefore be counted. In a sense, the context model defines what 'meaning' means.
The particular context model used is one of three described by Baroni and Lenci in their 2010 paper, in which they argue for a task-independent vector-based representation—a three-dimensional tensor—which can be matricized for different tasks as appropriate. This idea of a single representation capable of being used for multiple tasks runs contrary to common practice, in which researchers have developed specialized task-based representations. Few would dispute the need for different statistics for different tasks; certain tasks—-semantic similarity and synonym detection, for instance—-require a means of comparing words while other tasks—relation comparison, for instance—require a means of comparing pairs of words. However, there are also compelling reasons--parsimony, for one, and simplicity for another--for using only one representation that can be adapted as necessary. Since for this project, we are only interested in semantic similarity, the matrix used in all subsequent phases is of the former sort, referred to by the authors as W1xLW2 space, where W indicates a word and L indicates a dependency relation, or link, and the x divides the row-discriminator from the column-discriminator.
The specific model within the paper which this project implements is called DepDM and it is based on the intuition that paths in a dependency parse tree are similar to the semantic relations between words. This model was chosen for its simplicity; other more complex models in the paper performed better in tests performed by the authors. Formally, the context model consists of a set of tuples, each of which represents a different sort of meaningful context. Each tuple consists of (1) a name, (2) a function which returns true when given input that matches that particular context and false otherwise and (3) two indices that indicate which words in a matching dependency parse are connecting meaningfully, and which must as a result be stored in the co-occurence matrix. For example, one tuple named subj_intr captures the relationship between the subject and verb, when the verb is intransitive. Its function returns true when the input contains a noun that is the subject of a verb, which verb has no direct object. A dependency parse of the sentence The teacher is singing. matches and would be stored in the tensor as <teacher, sbj_intr, sing>. Two things are noteworthy about this triple. Firstly, notice that the words in it are lemmatized; the word singing was changed to its root form, sing. Unfortunately, for this project we did not use lemmatization. Secondly, the link sbj_intr is delexicalized, that is, it is a symbol and not a word from the lexicon. For all tuples but those that define prepositional context, links are delexicalized; for the tuples defining preposition context, the link is the preposition itself. Baroni and Lenci do not offer a theoretical explanation for why this is the case, but we speculate that discriminating between prepositions could reveal interesting properties. For instance, the prepositions upon and atop suggest something about surface characteristics completely unrelated to the characteristics suggested by the preposition through. However, every decision to add complexity to the model comes at a definite computational cost and a potential performance cost as well.
Fig. 7 Each tuple in the context model consists of a name, a function, and indices in a path through the graphical representaiton of dependency parse tree that must be stored.
One final note regarding the context model's tuples. Although in the case of sbj_intr, the pattern's features translate intuitively to dependency features, that is not always the case. For example, in order to properly capture the indirect object relationship, five separate tuples were needed. As only examples of matching sentences, and not the exact criteria, are specified in the original paper, the functions in these triples had to be reverse-engineered. The full list of tuples used by the context model, along with supporting examples, is carefully documented in ContextModel.java.
Implementation
As described previously, the distributional component is broadly responsible for constructing the co-occurrence matrix, given the corpus and the context model such that entry mi,j in co-occurrence matrix M represents the frequency with which wordi occurs with contextj. Here, we describe how these pieces were implemented. The process consists of two phases. First, each N-gram in the corpus must be represented graphically. Then, using the graph and the context model, the graph must be traversed and the statistics of meaningful co-occurrences compiled in a tensor. Finally, the tensor is matricized, reducing it to the two-dimensional sparse co-occurence matrix, which serves as the input to DISSECT. It seems roundabout to construct a tensor only to matricize it immediately thereafter but it is the intent of Baroni and Lenci, the original designers of this model, that each of the four possible matricized forms of the tensor is suited for a different set of tasks. Thus, it is in the interest of a single, task-independent representation that we construct the tensor, even though the scope of this project requires only one particular matricized form.
The first phase takes place in the N-Gram Parser. The N-Gram parser accepts a file consisting of biarcs and frequency counts and builds an intermediate graphical representation of nodes and edges similar to the one that appears in Figure 5. (It should be noted that, as every subset of the Syntactic N-Grams corpus uses the same format, the N-Gram Parser could accept the arcs subset, or any other subset and it's this flexibility which gave rise to the parser's name.) The input file consists of lines such as:
based both/DT/nsubjpass/3 only/RB/advmod/3 based/VBN/ROOT/0 11 1909,9 2005,2
Fig. 8 This biarc corresponds to a graph with three nodes ('both', 'only' and 'based'), in which the first two are dependents of the third via nsubjpass and advmod edges, respectively. The occurrence frequency is 11.
This line has four tab-separated parts, some of which have some sub-structure. The first part is simply the root word of the tree fragment which in this case is based. The second part is the tree-fragment itself, which consists of words with both part-of-speech (POS) tags, dependency edges and a number specifying the index of their governing word (which, when 0, indicates that the word has no governor) all delimited by forward-slashes. The final two parts contain information about the frequency (the corpus includes years along with frequency to afford other interesting analytical possibilities) although for this project, we ignore the final part, effectively collapsing the corpus over time.
For reasons that will become clear when discussing how the graph is used, the nodes and edges in the graph produced by N-Gram Parser belong to class hierarchies reflecting linguistic theories of part of speech and dependency relationships respectively. Thus, when creating the graph, the nodes and edges are instantiated as objects of their POS/dependency type. For example, a word tagged with the VBD tag would become a VBDNode, which belongs to the superclass VBNode (for verbs), which in turn belongs to the superclass PartOfSpeechNode. Since there are many competing versions of dependency theory, it is important to note that we modeled the dependency hierarchy after Stanford's most recent manual, but were forced to supplement this list with dependencies from a prior version after it became clear that the corpus used some slightly out-of-date tags.
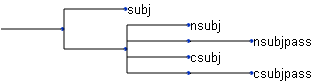
Fig. 9 A small piece of the Stanford dependency hierarchy. In this example, a dependency of type csubjpass is an instance of csubj and subj but not an instance of nsubj or any of its children.
The second phase of the process involves mining the graph of each N-Gram and extracting meaningful co-occurrences, as determined by the context model. Recall that every tuple in the context model contains a function that returns true for matching contexts and false otherwise. This second phase essentially consists of applying the functions of the tuples in the context model to the graph in turn, and taking action as appropriate. Thus, in describing the implementation, we focus mainly on the implementation of these functions within the context model.
The principal challenge in designing functions capable of matching tuples in the context model to paths in a graph is that for many of the tuples, there is no single feature in the graph that would indicate a match. For example, the dobj pattern does have an analogous dependency label named, fittingly, dobj, and so any path consisting of a noun, the dobj dependency, and a verb would match against the dobj pattern. Rather, in many cases, like the sbj_intr pattern mentioned previously, a matching path must meet some complex criteria. The nature of these criteria determined many of the design decisions. In the case of sbj_intr, those criteria are a sequence of noun (1) governed by a verb (2) via a dependency that is not passive (3) which verb has no direct object (4). (See figure 6.) The first and second criteria require a means of selecting nodes in the graph on the basis of POS tags. The third and fourth criteria require a means of selecting edges on the basis of dependency edge type. In both cases, given that both POS tags and dependency edges have hierarchies (for example, a verb gerund is a sort of verb and all but root dependency edges are instances of dep in the Stanford dependency hierarchy), it made sense to (1) incorporate the hierarchy and (2) exploit it whenever possible in order to express the patterns in a maximally general way. The class hierarchy allowed Java's instanceof to be used to make general and specific tests. See figure 8 for examples of the sorts of tests that are easily supported.
sbj_intr = new DependencyPattern("sbj_intr", new PredicateFunction[]{isnoun, togov, isnsubjnotpass, isverb, todep, isnotdobj, isnode}, 0, 1);
Fig. 10 How the triple sbj_intr is defined in the code. Note that a triple consists of a name, an array of predicates, and numbers indicating which words are to be stored in the tensor.
The actual graph traversal is done with a simple depth-first graph-search, modified slightly for performance reasons (there are many sorts of nodes that will never signal the start of an interesting path). However, similarities in the target patterns are not exploited to the fullest extent possible during the search, for reasons having simply to do with implementation time. As a result, the construction time for the co-occurrence matrix, which currently stands at about 20 hours when using the N-Gram Corpus on our local cluster, could be reduced. However, the implementation cost and the potential reduction in run time are comparable, and so this was deprioritized. This feature could be added at a later time. At each stage of the recursive search, a node selects and returns either its governor--if it matches the pattern--or the set of dependents that meet the criteria defined in the pattern. This was implemented by passing the node a function from the context model, such as the one below, which could be used to select nodes that are descendents of VBNode in the hierarchy.
static final PartOfSpeechNodeFunction isverb = new PartOfSpeechNodeFunction() {
@Override
public boolean checkNode(PartOfSpeechNode partOfSpeechNode) {
return partOfSpeechNode instanceof VBNode;
}
public String toString() {
return "VERB";
}
};
Fig. 11 Defining a function which will return true if applied to a dependent that is a descendent of VBNode (e.g., all verbs) and false otherwise.
The resulting path is a sequence of nodes and edges, such as <teacher, nsubj, sing>. This result, along with the frequency extracted from the corpus, can then immediately be stored in the tensor using the formatting information from the original pattern. Because these co-occurrences are thought to be informative independent of direction, the same sequence in reverse is also stored in the tensor.
Running the N-Gram Parser is quite simple. After compiling the Java source files, type:
>java DistributionalModel <n_grams_file>
which will produce three files that will be used by the Python code described next.
Building the Semantic Space
Once the Distributional Model has created the co-occurrence matrix, we can use the DISSECT software to build the semantic space, which is where all operations on word meaning will take place. DISSECT makes it extremely easy to both create semantic spaces and compose them. Although DISSECT's tutorial code should suffice for our ends, we nonetheless created a standalone Python file called transformSpace.py which accepts the output from the NGram Parser and builds a Space object.
Because raw frequency counts are known to be problematic for semantic comparison, the frequency is replaced by other statistics. These statistics are information-theoretic in nature and capture the informativeness of the frequency relative to what might be expected, given other values in the matrix. DISSECT offers various options, including positive point-wise mutual information (PPMI), positive local mutual information (PLMI), and others.
With the weighted Space object, we can now perform dimensionality reduction, which will improve performance as well as make prominent any latent structure in the matrix. DISSECT offers both singular value decomposition (SVD) as well as non-negative matrix factorization, though we only test the former. Performing dimensionality reduction is done using reduceDimensionality.py which anticipates not having a specific dimension in mind and expects instead a minimum, maximum and step size, and will generate reduced versions of the model for all steps in that range.
Because natural language is used for so many different ends, there are many ways by which we could measure the performance of natural language processing systems. And it's the versatility of human beings to accomplish these tasks with subconscious ease that inspired Baroni and Lenci to design a model that was task-independent. However, the scope of this project was limited to semantic similarity, and so most of this section will be dedicated to exploring the project's performance in that respect. Nevertheless, it must be noted that this remains the tip of a very large iceberg that includes tasks like the detection of synonyms, the comparison of analogies, the classification and categorization of nouns and many others. In its current state, nothing would need to be modified in order for the present system to be applied to these sorts of tasks.
Before looking at the project's performance with respect to some standards of semantic similarity, we begin with an anecdotal account that we hope will be instructive with regard to how the project can be used and which also demonstrates some of the limits of the methods used here. One such limit is that the model assumes each word has one and only one meaning. That is, every instance of bank has the same representation, even though we know that some instances refer to financial institutions and others refer to edges of rivers. Ideally, instead of a word-context matrix, we would construct a sense-context matrix, which would compile context statistics for each sense independently, but constructing such a matrix would require both a sense inventory and knowledge of which sense was being used. In other words, we would need to have already solved the problems of word sense induction (WSI) and word sense disambiguation (WSD). And, since WSI and WSD are both applications of computational lexical semantics, we have an unavoidable chicken-and-egg problem: we can't do what we are attempting properly until we've already done it.
The first anecdotal question we explore is simply, 'Do we observe some of these anticipated effects of polysemy?' To answer this question, we present the list of three nearest neighbors for a few polysemous words. The results are sobering. (Also, they are representative: extending to the 10th nearest neighbours would have made for an unwieldy table and would not have yielded any significantly different examples for any of the three cases.)
Fig. 12 The nearest neighbours of a word do not always accord with what we might expect or capture every aspect of a word's meaning.
The first result demonstrates how the meaning of bank is dominated by one sense, possibly because the corpus itself has more examples of one sense than another. The second result was unexpected and shows how words that are proper nouns in addition to regular words can have their meanings distorted dramatically. It also shows the importance of entity recognition, which could theoretically recognize members of categories like Person and replace them with their categorical labels. The third result illustrates the limitations of the distributional hypothesis: contextual similarity is not sufficient by itself to infer similar meaning, though in practice it often works, as evidenced by the fact that 2/3 of three nearest neighbors are very similar. Here, the antonym small's proximity to big can be explained by the possibility that the set of things to which the property big is applied overlaps considerably with the set of things to which the property small is applied, which makes perfect sense as an informal definition of things that can have spatial extent. Nevertheless, even though there are problems, for an unsupervised method using a very simple model, performance with respect to a number of benchmarks is still decent.
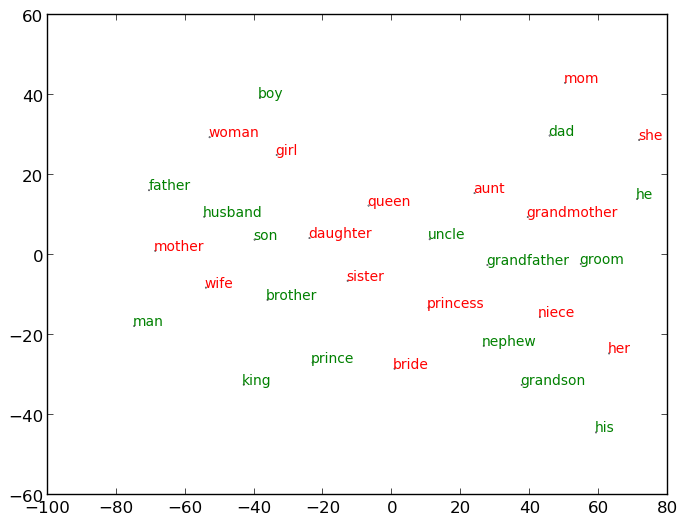
The second anecdotal question we explore is, 'Do we observe patterns in the meanings of words that accord with everyday conceptual relationships?' To answer this question, we look at male and female words plotted in a two-dimensional reduction of the model. (The model, before it is reduced, has thousands of dimensions but for the sake of practicality--it is much easier to work with vectors of fewer dimensions--and realism--limiting the number of dimensions corresponds to our theoretical belief that the true latent number of dimensions is finite, if unknowable--all measurment is done on a 90-dimensional reduction of the co-occurrence matrix.) If we were to examine a random collection of words, we would expect there to be no relationships in their positions in space (as a word's location in space--whether two-dimensional or 90-dimensional--is meant to capture its meaning). But, this is not a random collection of words, but rather words that belong to two distinct classes. Insted of being randomly distributed in space, we observe a small but measurable pattern in the relationship between a male word and its female counterpart: the latter tends to be up and to the right of the former, which is remarkable given that the input data contained no categorical information about gender or any other concept.
Fig. 13 A two-dimensional plot of 'male' and 'female' words showing a subtle relationship between the classes.
We now examine the project's performance with respect to semantic similarity benchmarks. Conveniently, there is a website that streamlines the measurement of semantic similarity in vector-based approaches to semantics by allowing one to upload a single file, which is then automatically compared against many datasets. We will briefly describe what semantic similarity is, how it is operationalized, its appeal and limitations as a measure, and then report how the project compares to other work. Firstly, semantic similarity is the similarity in meaning between two senses. For instance, intuitively, we know that dog and cat are somewhat similar (they are household pets with fur) while dog and monument are not. And this judgment is likely one that's available without much thought; we just know it. Most of the benchmarks for semantic similarity used here ask human subjects to self-report precisely how similar a finite set of words are, using a discrete scale. This task is quite artificial; rarely do we, in our everyday use of language, produce such conscious judgments using discrete scales, though we often have a sense of the relative similarity of words. Ideally, the benchmark, which is inexpensive to obtain, would be representative of performance of the model across language as a whole, which is far too cost prohibitive to obtain, as no human subject would endure making the millions of judgments necessary to compare all words. As we'll see, the representativeness of any one measure is also questionable. Two exceptions to the above descriptions are worth noting: the MEN dataset avoids the issue of using discrete scales by asking subjects to pick the more similar of two pairs of words (without asking them to report precisely how similar either pair was). The Radinsky dataset attempts to maximize the representativeness of the set of words chosen for the benchmark by selecting them on an objective basis, mutual informativeness, as opposed to selecting the words by hand. Radinsky also observes one potential problem inherent to all benchmarks derived from human judgments: they may not accord with established consensus. For instance, human subjects, perhaps reflecting a popular misconception that psychology is mostly theraputic, rated psychology and health highly similar, despite the fact that psychology also refers to the study of many phenomena of the mind that have no therapeutic application. This tension between the way language is used in practice and the way it 'should' be used is the essence of the descriptivist/prescriptivist debate that rages on in linguistics.
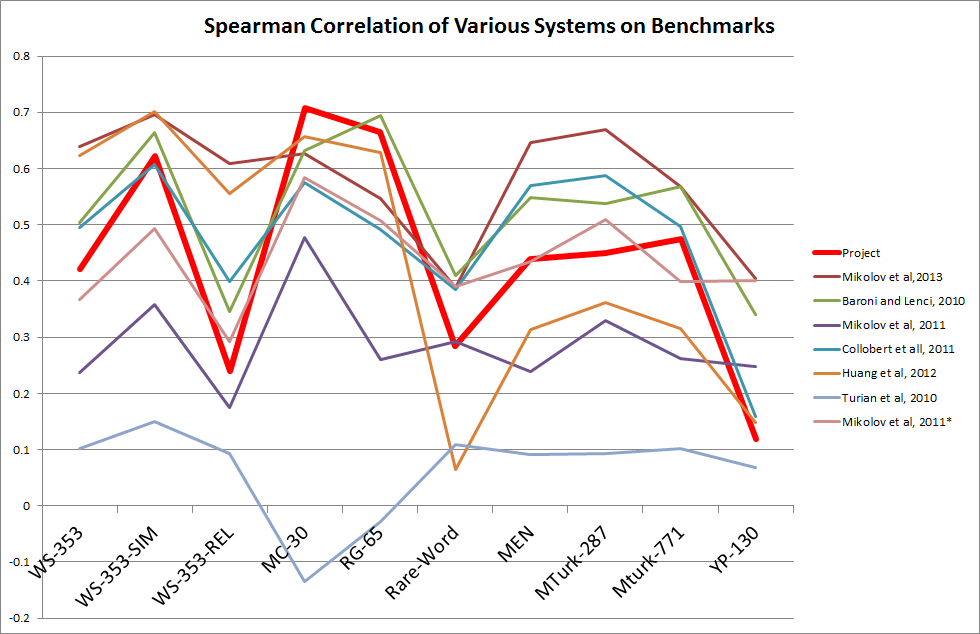
Using the aforementioned website, we examine performance on ten different benchmarks. We include two additional models for comparison. Mikolov 2013 is an oft-cited and high-performing model that uses a neural network and a model of context called the skip-gram. Baroni 2010 is one of three models described in the paper that inspired this project, though not the same model as was implemented. For context, wordvectors.org lists other models, most of which perform worse than the ones compared here. It is notable, firstly, that the project is within 20% of the other two for all benchmarks. Ideally, we would have liked to have compared Baroni and Lenci's implementation of the very same model as was implemented in the project, however this is not publicly available for download. However, the paper does mention that this model, known as DepDM, yielded a correlation coefficient of .57 on the Rubenstein and Goodenough benchmark, shown in the figure below as RG-65 and this number is .9 less than the .66 that the project yielded. More important than the quality of any single model are the trends that appear across all three, the most striking of which is their agreement with each other; between Baroni and Lenci and the current work, the correspondence is not surprisingly quite high (.96), whereas between the correspondence of these two with Mikolov is .58 and .54 respectively. But more important is the sheer range between the benchmarks, the size of which makes their individual representativeness a concern.
Fig. 14 The performance of three different distributional models on ten semantic-similarity benchmarks.
Conclusion
In conclusion, computational semantics has all the hallmarks of an active field of research; there is substantial variance in the performance of top systems and between various benchmarks. The project, despite being mainly for educational purposes, nevertheless performs in the middle of pack of the systems that were compared.
References
Dinu, N. Pham and M. Baroni. 2013. DISSECT: DIStributional SEmantics Composition Toolkit. Proceedings of the System Demonstrations of ACL 2013 (51st Annual Meeting of the Association for Computational Linguistics).
Cave, L. (2014, July 29). Lea Michele To Appear In ‘Sons Of Anarchy’. Retrieved August 8, 2014, from http://www.thehollywoodnews.com/2014/07/29/lea-michele-to-appear-in-sons-of-anarchy/
Sherwell, P. (2014, June 28). Hollywood star Shia LaBeouf appears in court after arrest at Broadway show. Retrieved August 8, 2014, from http://www.telegraph.co.uk/news/celebritynews/10932288/Hollywood-star-Shia-LaBeouf-appears-in-court-after-arrest-at-Broadway-show.html
Davies, M. (2014, June 28). BYU Corpus. Retrieved August 8, 2014, from http://corpus.byu.edu/corpora.asp
Jaime Huerta-Cepas, Joaquín Dopazo and Toni Gabaldón. ETE: a python Environment for Tree Exploration. BMC Bioinformatics 2010, 11:24.
De Marneffe, Marie-Catherine, and Christopher D. Manning. "The Stanford typed dependencies representation." Coling 2008: Proceedings of the workshop on Cross-Framework and Cross-Domain Parser Evaluation. Association for Computational Linguistics, 2008.
Faruqi, Manaal and Dyer, Chris. "Community Evaluation and Exchange of Word Vectors at wordvectors.org." Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics, 2014.
Goldberg, Yoav, and Jon Orwant. "A dataset of syntactic-ngrams over time from a very large corpus of english books." Second Joint Conference on Lexical and Computational Semantics (* SEM). Vol. 1. 2013.
Manning, Christopher D., Surdeanu, Mihai, Bauer, John, Finkel, Jenny, Bethard, Steven J., and McClosky, David. 2014. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 55-60.
Santorini, Beatrice. "Part-of-speech tagging guidelines for the Penn Treebank Project (3rd revision)." (1990).
Baroni, Marco, and Alessandro Lenci. "Distributional memory: A general framework for corpus-based semantics." Computational Linguistics 36.4 (2010): 673-721.
Erk, Katrin. "Vector space models of word meaning and phrase meaning: A survey." Language and Linguistics Compass 6.10 (2012): 635-653.
Navigli, Roberto. "Word sense disambiguation: A survey." ACM Computing Surveys (CSUR) 41.2 (2009): 10.
Radinsky, Kira, et al. "A word at a time: computing word relatedness using temporal semantic analysis." Proceedings of the 20th international conference on World wide web. ACM, 2011.
Eneko Agirre, Enrique Alfonseca, Keith Hall, Jana Kravalova, Marius Pasca, Aitor Soroa, A Study on Similarity and Relatedness Using Distributional and WordNet-based Approaches, In Proceedings of NAACL-HLT 2009.
Lev Finkelstein, Evgeniy Gabrilovich, Yossi Matias, Ehud Rivlin, Zach Solan, Gadi Wolfman, and Eytan Ruppin, "Placing Search in Context: The Concept Revisited", ACM Transactions on Information Systems, 20(1):116-131, January 2002.
Distributional Semantics in Technicolor E. Bruni, G. Boleda, M. Baroni and N. K. Tran. In proceedings of the ACL 2012 (50th Annual Meeting of the Association for Computational Linguistics), East Stroudsburg PA: ACL.
Mitchell, Jeff, and Mirella Lapata. "Composition in distributional models of semantics." Cognitive science 34.8 (2010): 1388-1429.
Turney, Peter D. "Domain and function: A dual-space model of semantic relations and compositions." arXiv preprint arXiv:1309.4035 (2013).